Structured Learning
ML is to find a function of f: $$ f:X \rightarrow Y $$
- Regression -> scalar
- Classification -> class (one-hot vector)
- Structured Learning ->
- Sequence
- 语音识别
- NLP
- ChatBot
- Matrix
- Image2Image
- Graph
- Tree…
Basic Idea of GAN
有两部分组成:
- 生成器Generator
- 判别器Discriminator
Generator
准确的说,Input的Vector的每一个值应该会代表某一个特征
Discriminator
GAN as Structured Learning
首先,我们有一个第一代的Generator,然后他产生一些图片,然后我们把这些图片和一些真实的图片丢到第一代的Discriminator里面去学习,让第一代的Discriminator能够真实的分辨生成的图片和真实的图片,然后我们又有了第二代的Generator,第二代的Generator产生的图片,能够骗过第一代的Discriminator,此时,我们在训练第二代的Discriminator,依次类推。
Algorithm
- Step 1 Fix generator G, and update discriminator D
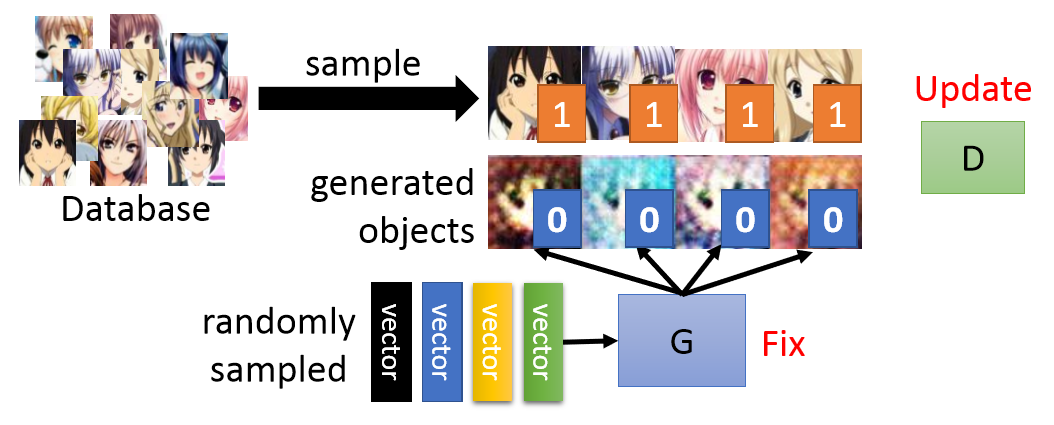
固定G,不断生成图片训练D,让D能够给真实图片高分,给生成图片低分。
- Step 2 Fix discriminator D, and update generator G
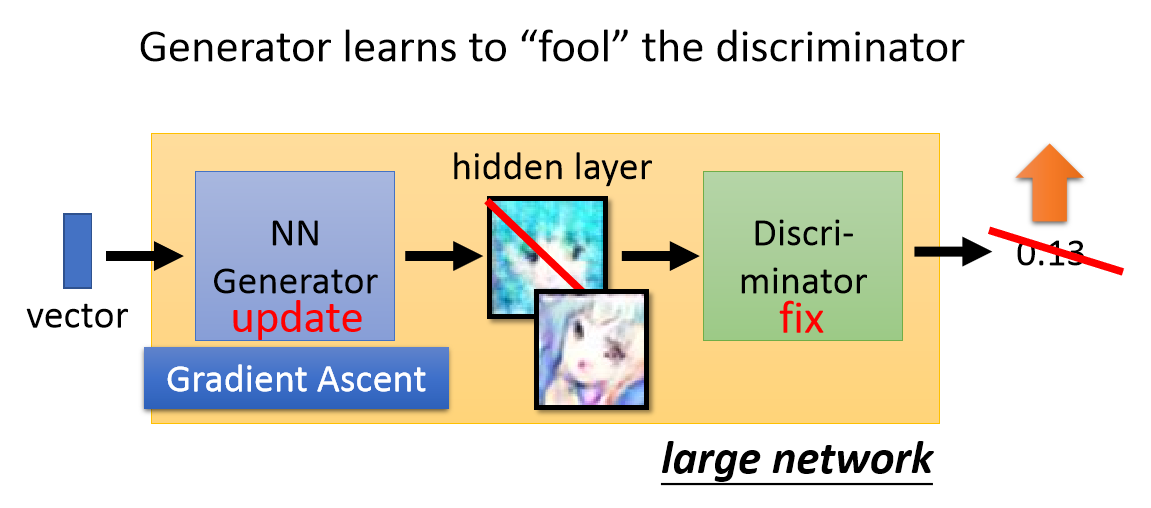
固定D,训练G生成能使D打高分的图片。
在第二步的时候,我们把G和D当做一个巨大的网络,中间有一个hidden layer会输出一个Flatten图片的大小。然后每次更新参数,只更新大网络前面G部分的网络参数。
Algorithm in Fake Code

为什么不能单G或单D?
- Generator是一个Bottom UP的问题。即Generator靠生成部件来组成整体,缺乏大局观,但是部件生成工作做得不错。
- Discriminator是一个Top Down的问题。即把控大局它很在行,但是很难做generate。
- 需要他们俩结合起来,就是GAN
单Generator
未尝不是没有解决办法的。可以使用Auto-Encoder来解决。
其实训练好的Auto-Encoder中的Decoder部分就可以作为一个Generator来用。
我们希望的是,AE能够学到的就是各个部分的细节,所以按道理来说,特征向量的部分改变应该会有对应的部件改变。也就是说:
如果用AE的话会发现$0.5 \times a + 0.5 \times b$会出现噪声,或者根本不是想要的结果。毕竟NN model又不是线性的。
那要如何解决这个问题呢?
VAE:Variational Auto-Encoder
所以这整套技术,单用Generator少了什么东西?What do we miss?
我们在把这整个过程当作Supervised Learning来Train的时候,追求的目标就是:和目标越像越好。但是如下情况:

error虽然少,但是却不合乎人手写数字的常理。因为各个neural之间没有联系。
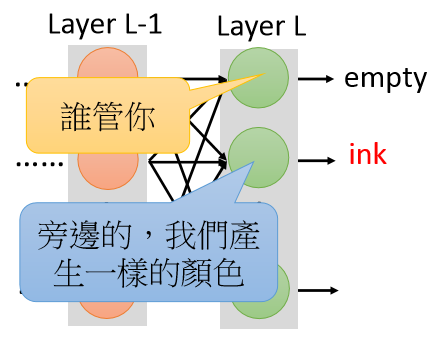
那么为了产生联系,可以多加几个layer,让neural在后面几层产生联系,所以,就会发现,单Generator要更大的network,才可以和一个简单的GAN的效果一样。
一个非常重要的点
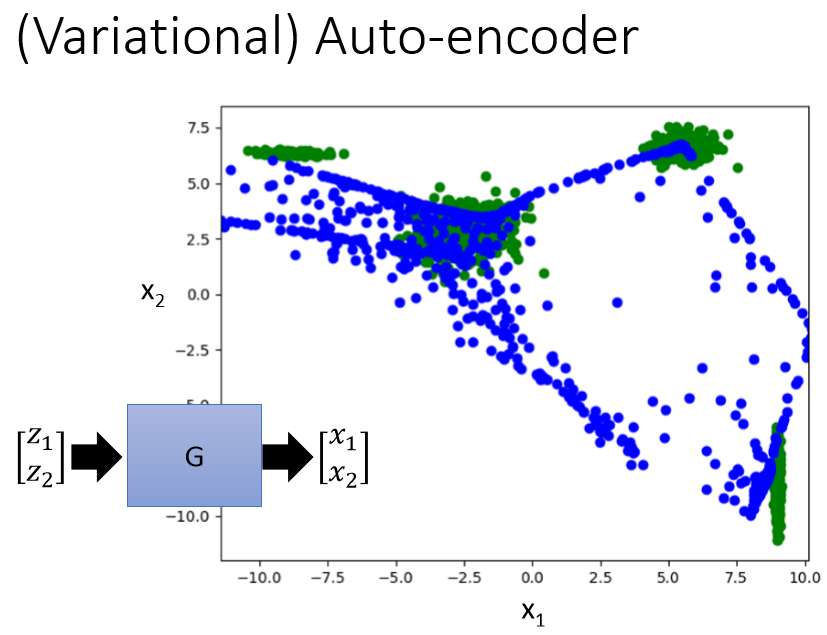
蓝色的点都是VAE生成的点,可以看到在中间过渡部分也产生了不少的蓝色点位。这就是VAE的问题所在。那么在异常检测的问题中也会存在这个问题。如果数据量少,或者数据分布不均匀,那么用AE或VAE学的模型就会学不到说中间的过渡部分的不好或者好。
单Discriminator
Discriminator经过Supervised Learning后可以很好的判断生成的结果好还是不好,那么要用他做Generator也不是不可以的。只不过得穷举。。。 $$\widetilde{x} = \underset{x \in X}{argmax} D(x)$$ 一直找到让D分数很高的图片就行。 >你还别说,Graphical Model里面很多其实都是用Discriminator来当Generator用的。在GAN里面就是用Generator来替代了