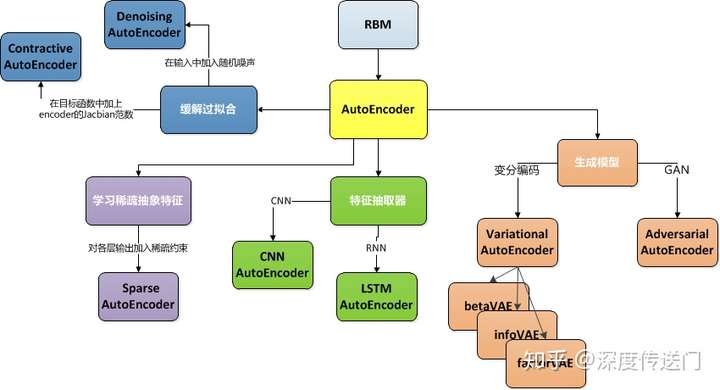
Auto-Encoder是一种无监督的学习算法,主要用于数据的降维或者特征的抽取
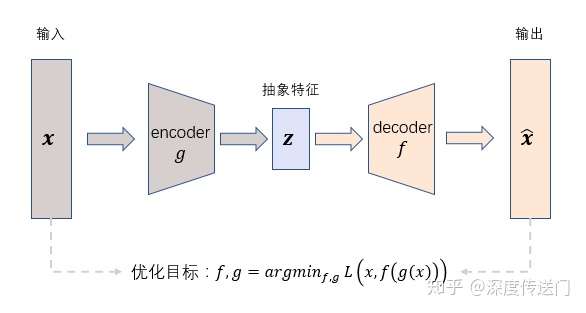
一个Encoder和一个Decoder组成,整个训练过程就是Encode后再Decode看看output和input差别大不大。这样取最中间的bottleneck层就好。
一般情况下,Encoder和Decoder的结构是互逆的。
因为自编码器学习如何根据训练期间从数据中发现的属性(即,输入特征向量之间的相关性)来压缩数据,所以这些模型通常仅能够重构与训练中观察到的模型相似的数据。
自编码器的应用包括: * 异常检测 * 数据去噪(例如图像,音频) * 图像修复 * 信息检索
用AE来做预训练
这个方法非常适合半监督学习或者监督学习时,有标签数据较少的情况。可以先用unlabeled数据利用AE的方式训练出每一层,再用labeled数据训练,调整参数即可。
De-noising Auto-Encoder去噪自动编码器(DAE)
在训练集的input上增加一些噪声,output标签数据集选择同一批干净的数据。这样能增加AE的鲁棒性,增加他抗噪声干扰的能力。
Contractive Auto-Encoder压缩自动编码器(CAE)
人们会期望对于非常相似的输入,学习的编码也会非常相似。我们可以为此训练我们的模型,以便通过要求隐藏层激活的导数相对于输入而言很小。换句话说,对于输入比较小的改动,我们仍然应该保持一个非常类似的编码状态。这与降噪自编码器相似,因为输入的小扰动本质上被认为是噪声,并且我们希望我们的模型对噪声具有很强的鲁棒性。降噪自编码器使重构函数(解码器)抵抗输入有限小的扰动,而压缩自编码器使特征提取函数(编码器)抵抗输入无限小的扰动。
因为我们明确地鼓励我们的模型学习一种编码,在这种编码中,类似的输入有类似的编码。我们基本上是迫使模型学习如何将输入的临近区域收缩到较小的输出临近区域。注意重构数据的斜率(即微分)对于输入数据的局部邻域来说基本为零。
Contractive Autoencoder(CAE)是Bengio等人在2011年提出的一种新的Autoencoder, 在传统的Autoencoder的重构误差上加上了新的惩罚项, 亦即编码器激活函数对于输入的雅克比矩阵(Jacobian matrix)的Frobenius Norm. CAE的核心思想是尽量捕获训练样本中观察到的variance, 而忽略其他的variance。
作者在围绕什么才是衡量特征好坏的标准上做了大量讨论(如同在DAE中一样)。
- sDAE(stacked DAE)和sparse coding的观点是尽量捕获每个训练样本的信息, 如果样本服从某个潜在的生成式分布的话。
- RBM的观点是学到的特征可以很好地刻画输入的分布, 这可以通过直接优化一个生成式模型(比如RBM)的似然得到。
CAE的出发点是, 学到的特征应该对围绕训练样本的输入的细小变动有鲁棒性。
为了提高学到的特征的鲁棒性, CAE以编码器的激活函数对于输入的雅克比矩阵的Frobenius Norm为惩罚项:
惩罚$|J_f|_F^2$项使得到特征空间的映射在训练样本的邻域是紧缩的(contractive).
CAE的思想就是以$|J_f|_F^2$项作为autoencoder的正则化项, 亦即CAE的损失函数为:
Hugo Larochelle做过一个关于CAE的非常精辟的理论解释:
可以把CAE的损失函数的两个组成部分看成是CAE的两个优化目标: 1. 第一部分(亦即重构误差)使得CAE会尽力去捕获输入图像的好多信息 2. 第二部分(亦即雅克比矩阵的Frobenius Norm)可以看做是CAE在丢弃所有的信息(因为最小化雅克比矩阵的Frobenius Norm的后果就是梯度会接近于0, 这样的话, 如果改变输入数据, 隐层单元的值不会改变, 亦即如果在训练样本上加一些噪音, 隐层节点的值不变). 所以CAE的目的就是只捕获那些在训练数据中出现的variance, 而对于其他的variance不敏感
Sparse AutoEncoder稀疏自编码器(SAE)
一般来说,自编码器的隐层节点数小于输入层的节点数,即在训练过程中,自编码器倾向于去学习数据内部的规律,例如相关性,那么自编码器学习的结果很可能类似于PCA,得到的是输入数据的一个降维表示。
那如果我们设定隐层节点数大于输入层节点数,同时又想得到输入数据内一些有趣的结构和规律。我们给自编器加上一个稀疏性的限制,即在同一时间,只有某些隐层节点是“活跃”的,这样整个自编码器就变成稀疏的。
假设隐层激活函数采用的是sigmoid,那么隐层输出为1代表这个节点很”活跃”,隐层输出为0代表这个节点”不活跃”。基于此,我们引入KL离散度来衡量某个隐层节点的平均激活输出和我们设定的稀疏度$\rho$之间的相似性:
其中
,$m$为训练样本的个数,$a^{(2)}_j{x^{(i)}}$为隐层第$j$个节点对$i$个样本的响应输出。一般来说我们设定稀疏系数$\rho=0.05或0.1$。KL离散度越大代表$\rho$和$\hat{\rho}_j$之间相差越大,KL离散度等于0代表两者完全相等$\rho=\hat{\rho}_j$。
因此,我们可以将KL离散度作为正则项加入到损失函数中,以此对整个自编码器网络的稀疏行进行约束:
TensorFlow实现
|
|
Variational AutoEncoder变分自编码器(VAE)
- VAE是一个改了中间层的自编码机。
- 基本思想来源:中间特征的泛化表示。
- 与一般的区别:一般的自编码机就是一个多层网络,中间的特征是一个固定的向量值。而VAE中间的特征是一种分布。
- 中间特征的抽象思考:1、如果输入是一个人脸图像,那么中间特征也许表示眼睛大小、肤色、头发种类等等等;2、类似于label smoothing一样,一个不确定的分布会更加符合人们事实的判断,就像去猜一个人的年龄一样,严谨的人会说他在20-25岁之间,而20-25岁的概率是基本符合正态分布的。
继续思考:
- 如果中间层的特征是一个分布,那么服从什么分布——正态分布
- 怎么才能让中间层表示一个正态分布呢?
- 正态分布无外乎是均值和权重就能控制的,那么我的中间层的激活值就是均值+权重
- 既然是自编码器那么整个网络的输入和输出要尽量相似。
- 神经网络的学习能力极好,既然我希望中间层是很多个正态分布的组合向量,那么我不如规定这些正态分布都满足0,1正态分布。
根据这些思考我们来定义损失函数:
损失函数是为了两个目的: 1. 所谓自编码,就是要还原自己的样子,所以输入和输出的比较是不可少的 2. 既然希望中间层满足0,1正态分布,那么我们就把输出的分布和0,1正态分布来做比较,那么分布与分布之间的比较使用到了KL散度,也是就是相对熵。
所以损失函数最后就出来了。通过反向传播,来达到目的。最后我们通过中间层的随机在正态分布上取值的手段就能生成类似的图像。
Adversarial AutoEncoder对抗自编码器
将GAN的思路引入AutoEncoder,也取得了不错的效果。
对抗自编码器的网络结构主要分成两大部分:自编码部分(上半部分)、GAN判别网络(下半部分)。整个框架也就是GAN和AutoEncoder框架二者的结合。训练过程分成两个阶段:首先是样本重构阶段,通过梯度下降更新自编码器encoder部分、以及decoder的参数、使得重构损失函数最小化;然后是正则化约束阶段,交替更新判别网络参数和生成网络(encoder部分)参数以此提高encoder部分混淆判别网络的能力。
一旦训练完毕,自编码器的encoder部分便学习到了从样本数据x到抽象特征z的映射关系。
